
TL;DR:
- Data processing converts raw, unorganized data into actionable insights through systematic steps like cleaning and transformation. It is essential for reliable analysis, strategic decision-making, and compliance with research regulations such as GDPR. Effective data processing requires disciplined practices, understanding workflows, and balancing automation with human oversight to prevent errors and delays.
Raw data is just noise. A spreadsheet full of unorganized survey responses, a database of customer transactions with missing fields, a research file with duplicate records — none of it means anything until it’s processed. Understanding what is data processing, and how it actually works, is the difference between organizations that make sharp decisions and those that guess. This guide breaks it down clearly, from the foundational definition to the methods professionals rely on every day.
Table of Contents
- Key takeaways
- What is data processing, exactly?
- The data processing lifecycle
- ETL vs. ELT: two approaches worth knowing
- Data processing in research and compliance
- Challenges and best practices in data processing
- My honest take on what most people miss
- Ready to put better data to work?
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Data processing has a clear definition | It is the systematic conversion of raw data into usable information through collection, cleaning, transformation, and storage. |
| ETL vs. ELT matters for your workflow | ELT is faster and more scalable in cloud environments, while ETL suits structured, legacy-driven pipelines. |
| Research processing has strict rules | GDPR and 2026 EDPB guidelines require pseudonymization, data minimization, and accountability for all research data. |
| Data prep eats most of your budget | Data preparation typically consumes 60 to 80% of project timelines and 25 to 40% of AI project budgets. |
| Quality beats volume every time | Reliable outputs depend on clean, well-governed data, not just large quantities of it. |
What is data processing, exactly?
Data processing is the systematic series of operations that converts raw, unorganized data into usable information for analysis, decision-making, and machine learning. Think of it as the engine underneath every insight your organization produces. Without it, data is just clutter.
The data processing definition spans a wide range of activities. You collect data from sources like surveys, sensors, or transactional systems. You clean it to remove errors. You transform it into formats that tools and analysts can actually use. Then you store it for retrieval and reporting. Each step serves a purpose, and skipping one almost always causes problems downstream.
Data processing also fuels business intelligence, automation, and strategic forecasting by transforming raw inputs into dashboards, customer analytics, and machine learning foundations. Whether you are running a market research study or managing enterprise operations, processed data is what separates a hunch from a fact.
The data processing lifecycle
Understanding how data processing works means walking through each stage. The process is not random. It follows a logical sequence, and knowing that sequence helps you spot where things go wrong.
- Data collection. Data enters the pipeline from structured sources like databases and forms, or unstructured ones like social media and open-ended survey responses. The quality of your input shapes everything that follows.
- Data cleaning. This is where errors, duplicates, missing values, and inconsistencies get resolved. It is tedious work, but it is also the most consequential. Dirty data produces unreliable analysis.
- Data transformation. Raw data gets converted into standardized formats. Units get normalized, categories get recoded, and fields get restructured so everything is compatible for analysis.
- Data aggregation and integration. Data from multiple sources gets combined. You might merge survey data with CRM records or blend transaction logs with behavioral data to create a fuller picture.
- Data sorting and filtering. Relevant records are isolated. Outliers are examined. The dataset gets shaped for its intended purpose.
- Storage and retrieval. Processed data lands in a warehouse, data lake, or cloud repository where it can be accessed for dashboards, reports, and further analysis.
Pro Tip: Start every project by documenting your data sources and expected formats before you collect a single record. Knowing what “clean” looks like ahead of time cuts your processing time significantly.
These steps support better decision-making because the output is trustworthy. Executives, analysts, and researchers all depend on this lifecycle working correctly. When it does, processed data becomes one of the most reliable tools an organization has.
ETL vs. ELT: two approaches worth knowing
The two most common data processing methods are ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform). They sound similar, but the difference in workflow has real consequences for speed, cost, and flexibility.
| Feature | ETL | ELT |
|---|---|---|
| Transformation timing | Before loading | After loading |
| Best environment | On-premises, structured data | Cloud-native, large-scale data |
| Speed | Slower for large volumes | Faster with elastic cloud compute |
| Flexibility | Limited once schema is set | High, transforms on demand |
| Common use case | Legacy warehouse migration | Modern analytics, ML pipelines |
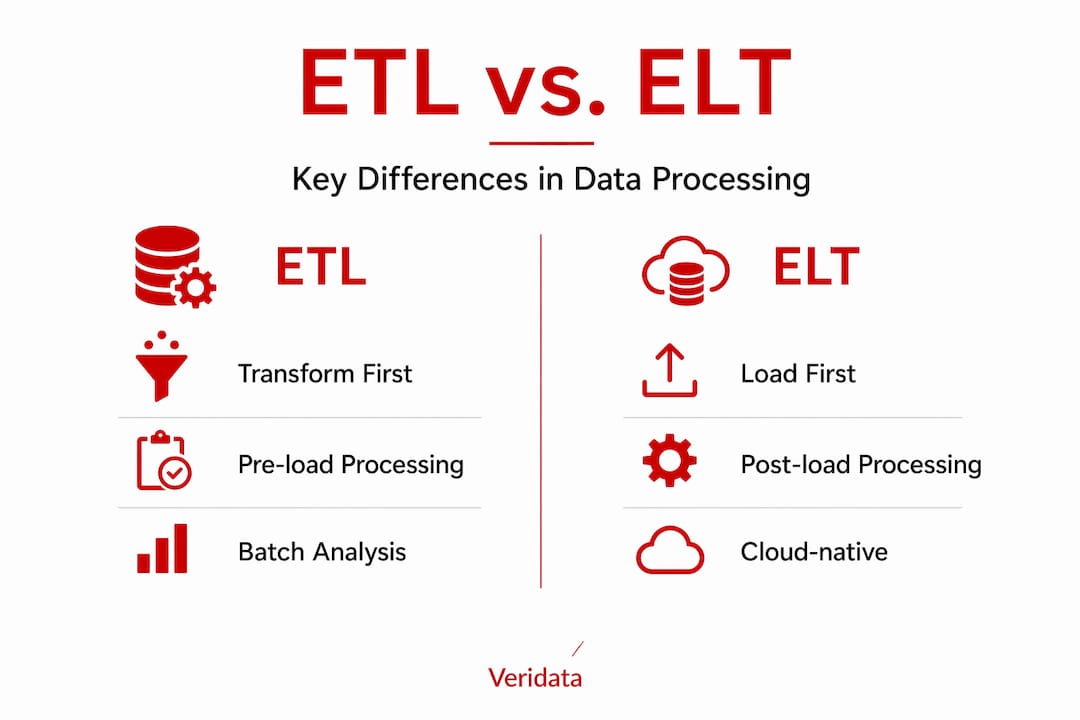
ETL has been the standard for decades. Effective ETL tools automate extraction, transformation, and loading from multiple sources into warehouses or lakes. It works well when your data structure is predictable and your destination system has strict schema requirements. The downside is that transforming data before loading slows ingestion, especially at scale.
ELT flips the order. Modern data integration has shifted toward ELT because it improves ingestion speed and scalability using cloud compute. Raw data loads into a central repository first, and transformation happens afterward, using the power of the cloud itself. This means you can run parallel transformations on massive datasets without preprocessing bottlenecks.
ELT pipelines load raw data directly into cloud storage and leverage elastic compute for on-demand transformations, enabling fast access and scalability. That makes ELT particularly well-suited for machine learning pipelines, where data scientists often need to re-transform the same raw data in multiple ways as models evolve.
A few things to keep in mind when choosing:
- ETL is a good fit if you work with legacy systems and highly regulated, structured data
- ELT suits organizations already operating in cloud environments with large, diverse data volumes
- ELT requires strong governance to prevent transformation mistakes on live data
- Both methods benefit from automation tools that enforce quality checks throughout the pipeline
Pro Tip: If you are evaluating a move from ETL to ELT, start with a non-critical dataset as a test. The migration process often surfaces governance gaps that are cheaper to fix before they reach production.
Data processing in research and compliance
Understanding what is data processing in research requires a slightly different lens. Research data often includes sensitive personal information, which means processing it correctly is not just a technical issue. It is a legal and ethical one.

The EDPB Guidelines 1/2026 make clear that organizations processing personal data for scientific research must apply strict accountability and pseudonymization safeguards under GDPR. Research is not a blanket exemption. Article 89(1) safeguards apply, and researchers must justify every step of their data use with documented purpose limitation.
The role of data processing in research also involves applying the right hierarchy of data protection. Per the EDPB 2026 guidelines, data minimization is required. The hierarchy favors anonymized data first, then pseudonymized data, with directly identifiable data used only when strictly necessary.
Practically, this means researchers should:
- Collect only the data points that directly answer the research question
- Apply pseudonymization at the earliest possible stage in the pipeline
- Document every processing activity with a clear lawful basis
- Avoid repurposing datasets without revisiting compliance requirements
- Work with research partners who understand data security practices and consent frameworks
Stricter governance and purpose limitation are now central to research data processing, making transparency and accountability non-negotiable. This is especially relevant for healthcare research, B2B surveys, and any study that handles identifiable participant data.
Challenges and best practices in data processing
Here is the uncomfortable truth about data processing examples from real projects: the work is harder and longer than most teams expect going in. The importance of data processing is routinely acknowledged in planning documents and routinely underestimated in practice.
73% of enterprise data leaders identify data quality and preparation as the top barrier to AI success. And 65% of AI deployments stall specifically because of data prep bottlenecks. Those are not abstract statistics. They describe real projects that missed deadlines and budgets because the data going into the model was not ready.
Data preparation consumes 60 to 80% of project timelines in most organizations. That figure surprises people who assume most of the effort goes into modeling or analysis. It does not. Getting the data clean and structured is where the time goes.
Financially, data preparation accounts for 25 to 40% of AI project budgets, while model development typically represents only 15 to 20%. Ignoring this ratio when scoping projects leads directly to budget surprises.
To avoid the most common traps:
- Audit data quality before committing to project timelines. What looks like a clean dataset rarely is.
- Build data cleaning time explicitly into your project schedule, not as an afterthought.
- Invest in data quality measures early rather than correcting downstream errors at higher cost.
- Use automation for repetitive transformation tasks, but keep human review in the loop for edge cases and anomalies.
- Treat AI data infrastructure investment as a core budget line, not an IT overhead item.
Pro Tip: Build a data quality scorecard at the start of every project. Track completeness, accuracy, and consistency across your key fields. It forces honest conversations early, when they are still cheap.
The organizations that get this right are not necessarily the ones with the most data. They are the ones with the most disciplined processing habits.
My honest take on what most people miss
I have worked on enough data projects to know that the biggest problem is not technical. It is a gap in expectations. Teams assume that collecting data is the hard part. In my experience, the collection is straightforward. The processing is where projects actually live or die.
What I have seen repeatedly is that the people making decisions about scope and timelines are often one or two steps removed from the actual processing work. They hear “we have the data” and assume it is ready to use. It almost never is. The cleaning, the reconciliation, the schema alignment, the validation loops — all of that takes time that rarely gets budgeted.
I have also noticed that the regulatory piece tends to get bolted on at the end. Especially in research projects. Organizations collect what they think they need, and then figure out compliance afterward. The EDPB 2026 guidelines are a clear signal that this approach is not going to fly anymore. You have to build governance into the processing workflow from the start, not retrofit it before publication.
The balance between automation and human oversight matters more than most tools vendors admit. Automation handles volume. Humans handle judgment. A processing pipeline with no human checkpoints will confidently produce the wrong answer at scale.
My suggestion: get genuinely curious about what is happening inside your data pipeline. Not just the outputs. The actual steps. That curiosity is what separates organizations that trust their data from those that just hope it is right.
— Daniel
Ready to put better data to work?
If this article clarified what data processing involves, you are already thinking more strategically about your data. At Veridatainsights, we handle every stage of that process for you. Our team covers data collection, processing and coding, analytics, and data visualization so your research delivers answers you can actually act on.
We work with B2B, B2C, healthcare, and hard-to-reach audiences. No project minimums. Seven days a week. Whether you need full-service support or just a hand with one stage of your pipeline, we are built for exactly that. See how we have done it in practice with our business services case study, or reach out directly to talk through your project.
FAQ
What is the basic data processing definition?
Data processing is the conversion of raw, unorganized data into structured, usable information through a series of steps including collection, cleaning, transformation, and storage. It is the foundation of any reliable analysis or business decision.
What are the main types of data processing?
The main types include batch processing, real-time processing, and stream processing. The right type depends on how quickly your use case requires results and how your data is collected.
What is data processing in research?
In research, data processing refers to handling collected data in ways that comply with ethical and legal standards, including anonymization, pseudonymization, and purpose limitation as required under frameworks like GDPR and the 2026 EDPB guidelines.
Why does data preparation take so long?
Data preparation often consumes 60 to 80% of a project’s timeline because raw data almost always contains errors, missing values, inconsistencies, and formatting issues that must be resolved before any analysis can begin.
What is the difference between ETL and ELT?
ETL transforms data before loading it into storage, while ELT loads raw data first and transforms it afterward using cloud compute. ELT is generally faster and more flexible for large-scale, cloud-native environments.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}